
Av Hans Petter Kjæstad, førsteamanuensis Veterinærhøgskolen, NMBU
Publisert 28. mai 2018 kl. 16:04
Som doktorgradskandidat ved mitt alma mater en gang i forrige århundre tok jeg det såkalte dr.scient.-kurset. Min foreleser understreket at signifikansnivået ikke måtte behandles lettsindig, og at det var noe en alltid fastsatte før en analyserte sine tall. Han spurte retorisk «Hva gjør du hvis resultatene dine viser seg å ikke være fullt ut statistisk signifikante, bare nesten?» En av kursdeltakerne dristet seg til å skyte inn: «Da justerer vi bare signifikansnivået!» Professorens hoderystende latter viste at forslaget ikke var stuerent. Vår ytterst kompetente professor foreleste på linje med et utall professorer både før og etter ham. Men det var min medstudent som hadde rett! Signifikansnivået må bestemmes etter analysen.
Som kjent uttrykker p-verdien sannsynligheten for at effekten en mener å spore i sine tall, skyldes tilfeldighet, dvs. at effekten egentlig ikke eksisterer. Den tallfester altså risikoen for tap, dermed også sjansen for gevinst, dersom en ville gamble på de aktuelle analyseresultatene.
Hvilken risiko for å ta feil er egentlig akseptabel; hvilken p-verdi er riktig?
Hva bør signifikansnivået være? Med andre ord: Hvilken risiko for å ta feil er egentlig akseptabel; hvilken p-verdi er riktig? Dette bør ingen svare på før de vet hva som står på spill. Det er rett og slett ikke rasjonelt å velge odds før en vet hvilken gevinst veddemålet har å by på, og det er odds det dreier seg om. Signifikansnivåene 0,05, 0,01 og 0,001 tilsvarer odds på henholdsvis 19 til 1, 99 til 1 og 999 til 1. En person som bare vedder når oddsene er minst 19 til 1, vil over tid tape stort i forhold til en som aksepterer noe høyere risiko.
La oss se på et tenkt forsøk der to nye, livsforlengende medikamenter til kreftpasienter er sammenliknet med dagens behandling.
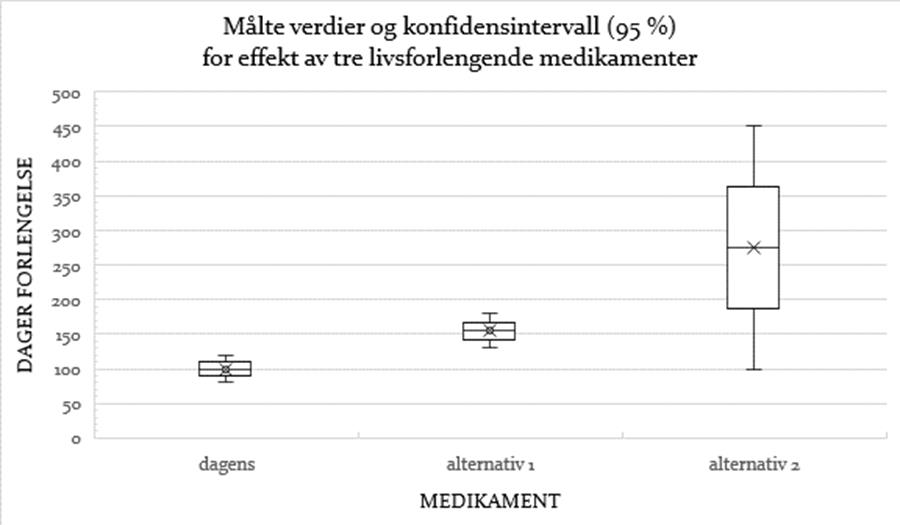
Resultatene kan vurderes på to måter, som her er satt på spissen:
Tolkning a): Alternativ 1 bør velges. Det har en sikker effekt på livslengden. Vi bør foreta mer forskning på alternativ 1, tallene kan tyde på at vi vil avsløre betydelige effekter på livslengde framover. Vi bør dessuten straks anbefale dette medikamentet framfor alternativ 2, da den tilsynelatende positive effekten av alternativ 2 ikke er statistisk signifikant, dvs. ikke forskjellig på 5 prosent-nivå fra dagens førstevalg.
Tolkning b): Alternativ 2 bør velges. Selv om alternativ 1 har vist seg å ha en viss effekt på livslengden, bør vi ikke velge det. Effekten av alternativ 1 viser liten variasjon, og det smale konfidensintervallet betyr at det er svært sikkert at effekten virkelig er akkurat så liten som vi her ser. Det vi skal anbefale leger som behandler slike pasienter, er alternativ 2. Der er det større variasjon, men også sjanse for meget god effekt.
Jeg er sikker på hvilket medikament en pasient burde valgt, men er ikke like sikker på hvordan en reviewer i et vitenskapelig tidsskrift ville vurdert disse resultatene.
I tolkning a) er konklusjonene urimelige, og årsaken er ukritisk omgang med signifikansbegrepet. Tolkning b) fokuserer i stedet på størrelsen av effekten, det vi kan kalle reell/klinisk/økonomisk/biologisk signifikans eller tilsvarende. Jeg er sikker på hvilket medikament en pasient burde valgt, men er ikke like sikker på hvordan en reviewer i et vitenskapelig tidsskrift ville vurdert disse resultatene.
Forhåpentligvis illustrerer eksemplet at «signifikansnivået» rett og slett ikke kan være gjenstand for et rigid valg som gjøres før en har vurdert størrelsen på effekten. Det er vanskelig å tenke seg en eneste form for studie/analyse der det primære målet bør være å finne statistisk signifikans. Målet er å estimere størrelsen på en mulig effekt og diskutere hva som er rimelige odds for å skulle satse på at den er reell.
Det som nå er sagt, virker muligens temmelig innlysende, slik at den oppegående forsker kanskje vil mene at denne typen feilslutning ikke gjelder henne. Det er en konklusjon jeg ville vært forsiktig med. Bare et kort dykk ned i vitenskapelige artikler produsert ved universitetene våre i foregående år, vil vise at signifikansrytteriet lever i beste velgående*.
Erfaring viser at de nærmer seg signifikansbegrepet med misforstått ærefrykt
Hvorfor er denne øvelsen så vanlig? For det første blir alle forskerspirer grundig drillet i hypotesetestingsritualene. Både underviser og lærebok stopper dessverre gjerne der, og lar det være opp til forskerne å håndtere resten av resonnementet. Det kan jo gå bra, men erfaring viser at de i stedet nærmer seg signifikansbegrepet med misforstått ærefrykt overfor statistikkpensum.
Programvaren en bruker til statistisk analyse, kan bidra til denne holdningen, som når manualen frister med p-verdier som markeres med hele fire stjerner og kan ha opptil 15 desimaler (1). Problemet er faktisk til dels innebygd: Når en skal sette i gang den nokså vanlige prosedyren trinnvis multippel regresjonsanalyse, må en på forhånd legge inn ønsket signifikansnivå for forklaringsvariablene.
I et konferanseinnlegg (2) som oppsummerer deres tidligere bok (3) om problemet, hevder Ziliak og McCloskey å ha funnet selve erkesynderen i den historisk viktige statistikeren R. A. Fisher, mannen bak blant annet regresjons- og variansanalysen. Fisher var opptatt av statistisk signifikans, for å si det forsiktig.
En vurdering av reell signifikans vil åpne for diskusjon
Statistisk signifikans er dessuten trygt og nokså udiskutabelt. Ingen kommer til å tvile på at de høysignifikante resultatene dine virkelig er høysignifikante. Derimot vil en vurdering av reell signifikans åpne for diskusjon. Det er mindre trygt. Du kan få kritikk for en rekke vesentlige forhold, som verdivalg, resonnementer og konklusjoner. Vi skal heller ikke se bort fra det faktum at reell signifikans har en ubehagelig tendens til å glimre med sitt fravær. Hva har en da å vise til, om ikke nettopp statistisk signifikans?
Til slutt kan det minnes om at det eksisterer en uheldig språklig likhet mellom begrepene vi bruker: statistisk signifikans versus reell signifikans. De har likevel ingen ting med hverandre å gjøre. I engelsk språkdrakt blir det enda verre, da significant rett og slett betyr betydningsfull, viktig. Som en forhåpentligvis innser, kan ingen p-verdi i seg selv gjøre et resultat betydningsfullt.
Signifikansbegrepet bør kjøres på forskningens skraphaug sammen med stjerner og p-verdier i fete typer
For å konkludere: Eventuell forekomst av reell signifikans må påpekes og underbygges i en vitenskapelig artikkels diskusjonsdel. Hva står da igjen til resultatdelen? Det essensielle er uansett å estimere de aktuelle effektene i den bakenforliggende populasjonen. Estimatene bør presenteres som konfidensintervaller. Et 95 prosent konfidensintervall blir ofte valgt. I tråd med herværende resonnement er det imidlertid tillatt å velge andre intervallgrenser. Men signifikansbegrepet bør kjøres på forskningens skraphaug sammen med stjerner og p-verdier i fete typer.
* Om ønskelig kan en liste med noen eksempler fås ved å sende meg en e-post. Imidlertid kan hvem som helst få bekreftet at påstanden stemmer ved å gjøre sitt eget utvalg fra universitetenes publikasjonslister via den nasjonale forskningsdatabasen («Cristin»).
Referanser








